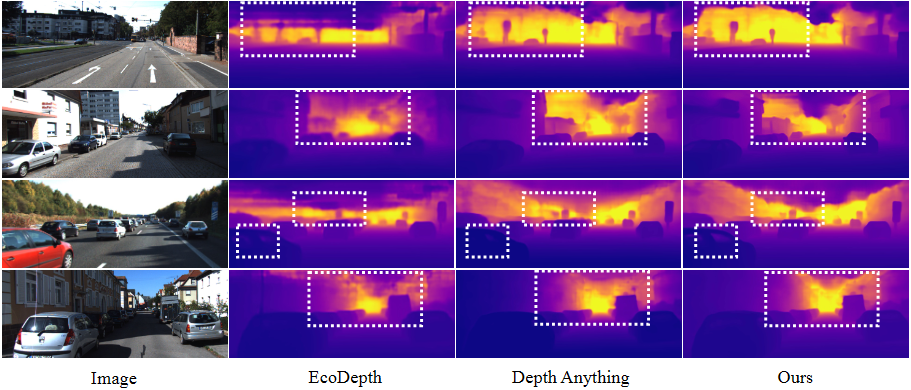
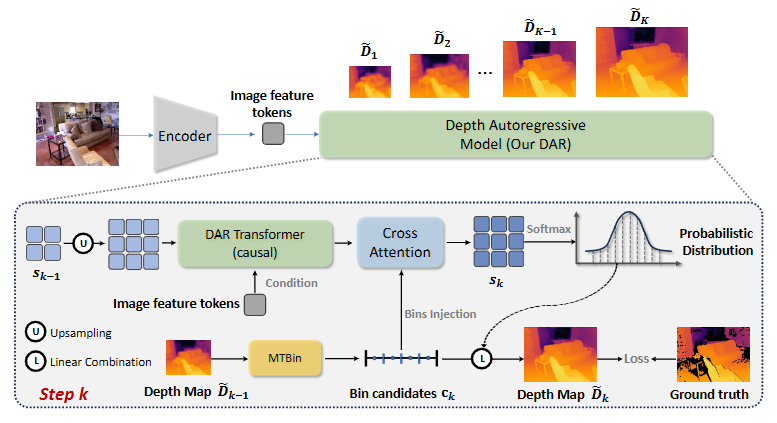
Motivation: Where is Autoregressive Objectives?
We exploit two “order” properties of the MDE task that can be transformed into two autoregressive objectives. (a) Resolution autoregressive objective: The generation of depth maps can follow a resolution order from low to high. For each step of the resolution autoregressive process, the Transformer predicts the next higher-resolution token map conditioned on all the previous ones. (b) Granularity autoregressive objective: The range of depth values is ordered, from 0 to specific max values. For each step of the granularity autoregressive process, we increase exponentially the number of bins (e.g., doubling the bin number), and utilize the previous predictions to predict a more refined depth with a smaller and more refined granularity.
Motivated by this, we propose DAR, which cast the MDE into autoregressive framework that aims to perform these two autoregressive processes simultaneously.
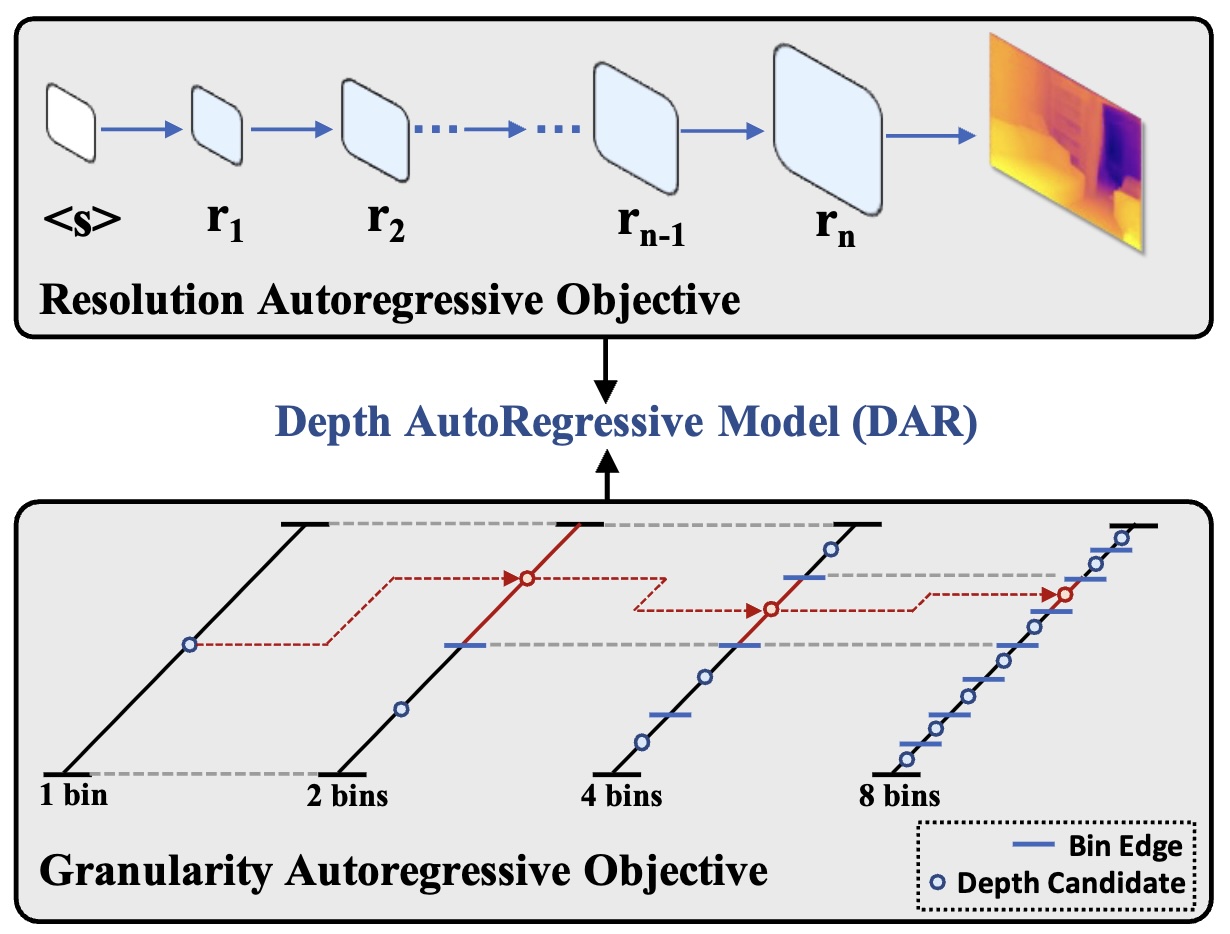 Motivation: Two 'order' properties that naturally become autoregressive objectives.
Motivation: Two 'order' properties that naturally become autoregressive objectives.
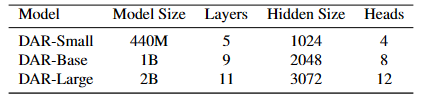
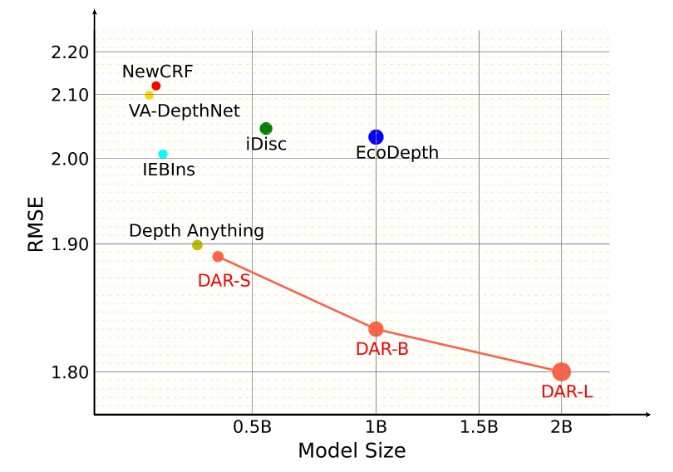 RMSE performances (↓) vs. model sizes on the KITTI dataset.
RMSE performances (↓) vs. model sizes on the KITTI dataset.